������������Wվ��������Ҫ��Դ���Wվ���������Ȼ�Ǵ־Wվ�\�I�ˆT�P�ĵĆ��}��
�����_һЩ�����c��һ���W퓱�����c���Ѓɂ����أ�
�Ƿ����x���^
����|���Ƿ��^�P
֮ǰ���^��������@ôһ��ָ�ˣ��ܶ�Wվ���е�ȥ���@��ָ�ˣ����ҿ���site�Ĕ�����������!�������ϛ]���@��ָ�ˣ��ܶ���͟o�����֡��Ĕ������ҳ����}�����Ô���ָ����Q����������������C�����ɹ��� ������ˡ�����\�������������@�������X�ò��e���є��������ķ����v�ú����ӣ����h���dȤ�ď�����������ͬ�W�����I���������κΔ���������Ŀ��->����->�u��->�Q�����Ă��h���M�ɡ�
Ŀ�����҂��뿴һ�¾Wվ�������r��Σ���SEO�����Ƿ�߀����ߵęC����
�����������rʲô���ʲô��ģ��Dz�����һЩָ�ˁ�����?�Wվ�������r�Dz����^�ڻ\�y���Dz��Ǒ�ԓ�����¸������������r?
�u���������҂���Ҫ����һЩ����
�� �Wվ�����Ӽ��Pϵ
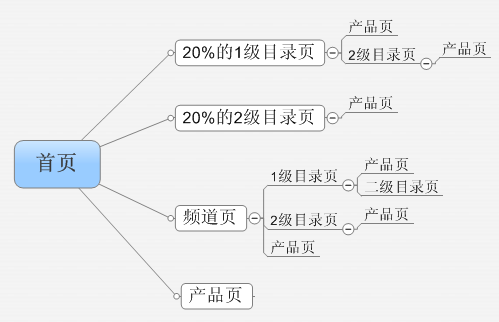
�������Ӽ���控����SEO����
�������Ӽ����������r���
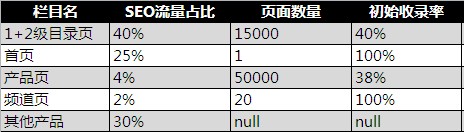
SEO������ռ�ȿ��ԏ�Google Analytics���^�V������
��攵�����ԏĔ�����@�ã�����ͨ�^��܇�^or����С�_��ץȡ�yӋ��
����ʿ��Ԍ��@ȡ�����ͨ�^�����M����������܇�^Ҳ���ԡ�
���}���R�@!
1+2��Ŀ�퓎����˴���������������ʲ��Ǻܺã�������䛵���������ͻ�ƿ��ڴ�!

�aƷ��攵���ܶ࣬���Ҳ���Ǻ����룬���ǎ������������ޣ�������䛆��}��߀�������ݵĆ��}���������Ȳ������ˡ�
�Q�����҂��ĽYՓ������չ�_�Єӌ�Ŀ�����M����䛵ă�����
�����@߅���ƺ����_ʼ��Ŀ�ˣ���ͨ�^�����������������
��׃�����µ�Ŀ�ˣ���������Ŀ������������
�@߅�ܲ����ٴ�ͨ�^���������ķ����M��SEO��?
���ǿ϶���!
�҂��ف�������һ�� Ŀ��->����->�u��->�Q�� ���^��
Ŀ�������Ŀ����������
������ͨ�^�����_ʼ�����P��䛵ăɂ����أ��҂���Ҫ�z��һ�£��W��Ƿ����x�����^���W퓵��|���Dz����^�P��
1. �P�����x����r���҂���Ҫ������־�����ܴ_���������҂�����־�в��һϵ�Д�����������Ƿ���ı������^��
2. ��������|���ƺ���һ�����y������ֵ�������҂���������ͬģ���µģ�
�ѱ����е���攵��/�ѱ����в��ұ������攵��
���u��ԓģ������|������䛵�Ӱ푴�С�������������涼������ˣ��������f���@�����ă�����������߀���J�ɡ�(���H��r�h���@�����s��������䛺�Ҳ�п�������|�����}���h����������ʲô���ն��]��Ҫ�ã�����!)
���J�Rȫ�����صĄ��I�ߡ����I���ң�������롰�Ї����IȦ��
|







